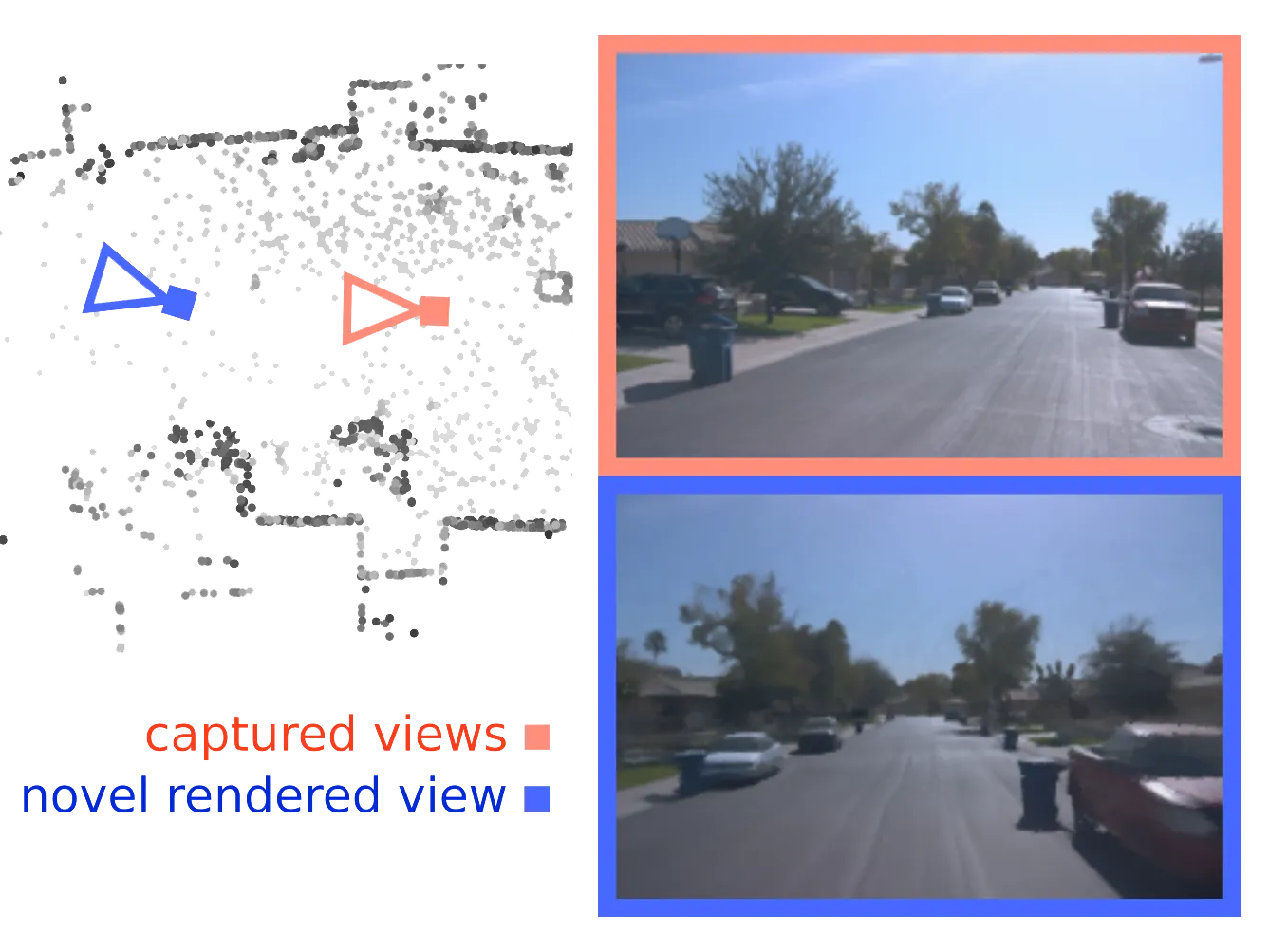
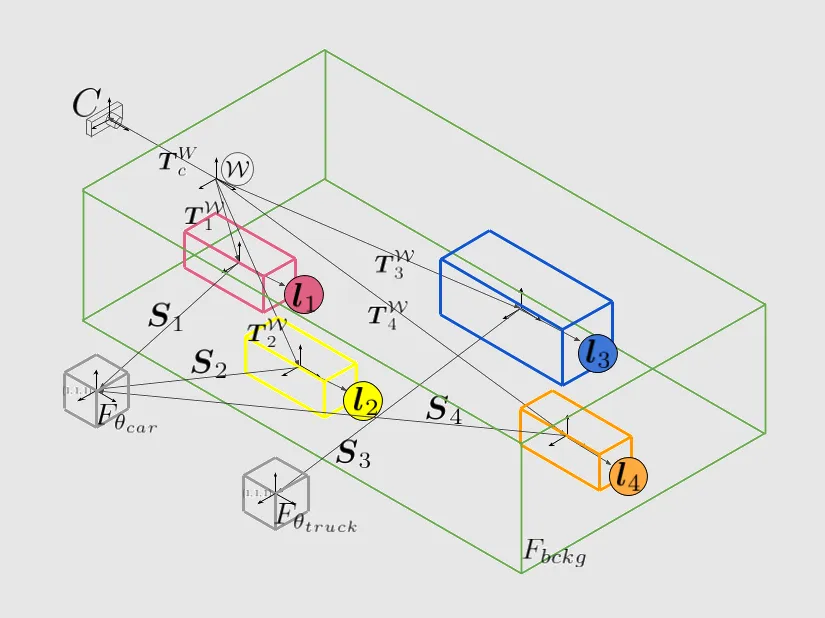
WorldFlow3D: Flowing Through 3D Distributions for Unbounded World Generation
Unbounded 3D world generation is emerging as a foundational task for scene modeling in computer vision, graphics, and robotics. We present WorldFlow3D, a novel method capable of generating unbounded 3D worlds. Building upon a foundational property of flow matching – defining a path of transport between two data distributions – we model 3D generation more generally as a problem of flowing through 3D data distributions, not limited to conditional denoising. Our latent-free flow approach generates causal and accurate 3D structure, and can use this as an intermediate distribution to guide the generation of more complex structure and high-quality texture – all while converging more rapidly than existing methods. We enable controllability over generated scenes with vectorized scene layout conditions for geometric structure control and visual texture control through scene attributes. We validate WorldFlow3D on both real outdoor driving scenes and synthetic indoor scenes, confirming cross-domain generalizability and high-quality generation.